Intro
3x3 격자판에서 진행하는 클래식한 틱택토 게임을 제작했다. 다른 사람과 함께 플레이하거나, 컴퓨터와 플레이하는 두 가지 모드로 구성되어 있다. 컴퓨터는 미니맥스 알고리즘에 따라 항상 최선의 선택을 하도록 구현했다.
틱택토는 오목과 비슷한 보드게임으로, 규칙은 다음과 같다.
- 두 명의 플레이어가 3x3 격자판에 번갈아가며 각자 자신의 표시(O 또는 X)를 기록한다.
- 같은 표시를 가로, 세로, 또는 대각선 상에 일직선으로 놓으면 승리한다.
8가지 승리 상황
■■■ □□□ □□□ ■□□ □■□ □□■ ■□□ □□■
□□□ ■■■ □□□ ■□□ □■□ □□■ □■□ □■□
□□□ □□□ ■■■ ■□□ □■□ □□■ □□■ ■□□ - 아래의 종료 조건 중 하나가 충족될 때까지 계속된다.
- 한 플레이어가 먼저 승리
- 더 이상 빈칸이 남지 않은 상황(무승부)
- 어느 한 플레이어가 종료를 요청
Design
- 게임판의 상태를 텍스트로 출력
- 2차원 리스트로 게임판을 생성한다.
- 새 게임이 시작되면 먼저 모든 칸을 빈 칸(
" ")으로 초기화한다. - 빈 칸이 남아있는지 확인하려면 게임판 전체를 확인하고 True/False 반환한다.
- 둘 중 한 플레이어가 승리했는지 확인하려면 8가지의 승리 상황과 같은지 확인한다.
- 게임 루프
- 원하는 모드 및 선공할 플레이어를 선택한다.
- 1p의 경우 사람이 선공/후공 선택 권한 소유
- 게임판의 현재 상태를 출력하고 다음 플레이어가 빈 칸 중 하나를 선택한다.
- 사람: 원하는 칸의 행과 열 번호를 순서대로 입력 (e.g. 23)
- 컴퓨터: 알고리즘을 통해 행과 열 번호를 선택
- 입력을 확인한다.
- 사람이 게임 종료 요청(
"00")을 입력했을 경우, 루프 종료 - 이미 선택된 칸을 고르거나 양식에 맞지 않게 입력한 경우, 메시지와 함께 다시 입력하도록 안내
- 빈 칸 중 하나가 선택됐을 경우, 해당 위치에 기호를 표시하고 게임판을 업데이트
- 사람이 게임 종료 요청(
- 업데이트된 게임판을 확인한다.
- 현재 플레이어가 승리했는지 확인 → 승리 상황인 경우, 승리한 플레이어에 대한 메시지를 출력하고 루프 종료
- 게임판에 빈 칸이 남았는지 확인 → 게임판이 가득찬 경우, 무승부 메시지를 출력하고 루프 종료
- 종료 조건이 아닐 경우, 다른 플레이어에게 턴 넘기기
- 게임이 종료될 때까지 루프를 무한 반복한다.
- 원하는 모드 및 선공할 플레이어를 선택한다.
Implementation
Tech Stack
- Programming Language: Python
- Environment: Terminal-based CLI
Coding
- 보드 상태 관리
- 2차원 배열 안에 O, X 또는 공백(빈 상태를 나타내는 값)이 들어간다.
- 시작 시 모든 원소를 공백으로 초기화한다.
- 게임 종료 체크
- 가로, 세로, 대각선에 같은 표시가 있는지 확인하는 방식으로 승자가 있는지 판별한다.
- 각 표시에 따라 다른 값을 반환해서 누가 승자인지 확인할 때 사용한다.
- 보드가 꽉 찼는지 체크
- 승자가 없고 보드가 꽉 찼다면 무승부로 처리한다.
- 한 칸에 표시가 마크될 때마다
marked_cells변수에 하나씩 카운트해서 그 값이 9가 됐을 경우 종료한다.
(매번 게임판을 순회하며 빈 칸을 찾을 필요가 없도록 시간 절약)
- 차례 관리
- 현재 플레이어가 누구인지 계속 추적한다.
- 게임이 종료되지 않았을 경우 다음 플레이어와 그 플레이어의 표시로 전환한다.
- 플레이어의 입력 확인
- 입력값이 유효한지 확인하고 범위를 벗어난 값을 입력했을 경우 계속 다시 입력받는다.
- 게임판에서 칸을 선택할 때는 선택한 위치가 빈 칸인지도 함께 확인해야 한다.
Computer AI
Minimax algorithm(최소극대화 알고리즘)을 활용해서 알고리즘을 만들었다. 이 규칙은 상대가 항상 나를 가장 불리하게 만드는 최적의 선택을 한다는 가정하에 내 차례에서 가장 좋은 선택을 하는 원리다. 틱택토, 체스, 오델로 등 2인이 플레이하는 게임에 널리 쓰이는 알고리즘이기 때문에 이 프로젝트에 적용시켜 보았다. 알고리즘이 잘 작동한다면 사람이 아무리 완벽히 플레이해도 AI를 이길 수 없다(비기는 것까지만 가능).
컴퓨터는 사람을 이기기 위해 다음과 같은 논리를 따른다.
X(컴퓨터): 이길 확률을 최대화(Maximize)하는 수를 선택
O(사람): 컴퓨터는 사람이 항상 컴퓨터가 이길 가능성을 최소화(Minimize)하는 최적의 수를 둔다고 가정
루프
- 현재 게임판 상태가 종료 조건에 속하지 않을 경우 게임판을 파이썬 내장 모듈 copy로 deep copy한다(실제 게임에 사용되는 게임판에 표시하면 안 되기 때문).
- 복사된 게임판에서 아래의 순서를 따른다.
- 보드의 각 칸을 순회하며 빈 칸을 수집
- 각 칸마다 기호를 표시한 후 재귀 호출하는 것을 반복
- 해당 칸에 수를 뒀을 경우 가능한 모든 다음 상황에 대해 살펴보는 것
- 모든 케이스마다 점수를 부여
- 게임판이 종료 조건을 만족하는 상태가 됐을 때 재귀 호출 스탑
- 각 케이스마다 점수를 확인하고 합산한다.
점수 평가법
가장 마지막 케이스(종료 조건이 되는 케이스)부터 점수 계산을 시작해서 위로 거슬러 올라간다.
- 게임 종료 케이스에서는 다음과 같이 계산한다.
- 컴퓨터가 이기는 상황:
+1의 점수 부여 - 컴퓨터가 지는(사람이 이기는) 상황:
-1의 점수 부여 - 비기는 상황:
0의 점수 부여
- 컴퓨터가 이기는 상황:
- 자식 케이스들이 있는 경우, 현재 턴에 따라 점수 계산 방식이 달라진다.
- 다음 차례가 컴퓨터: 자식 케이스들 중 가장 높은(max) 점수를 선택
- 다음 차례가 사람: 자식 케이스들 중 가장 낮은(min) 점수를 선택
Current Board
+---+---+---+
| | O | X |
+---+---+---+
| O | | X |
+---+---+---+
| X | | O |
+---+---+---+
next: human(●)
min(+1, -1, +1) = -1
👤Case 1 👤Case 2 👤Case 3
+---+---+---+ +---+---+---+ +---+---+---+
| ● | O | X | | | O | X | | | O | X |
+---+---+---+ +---+---+---+ +---+---+---+
| O | | X | | O | ● | X | | O | | X |
+---+---+---+ +---+---+---+ +---+---+---+
| X | | O | | X | | O | | X | ● | O |
+---+---+---+ +---+---+---+ +---+---+---+
next: com(✖) next: com(✖) next: com(✖)
max(+1, -1) = +1 max(-1, -1) = -1 max(-1, -1) = +1
🤖Case 1-1 🤖Case 1-2 🤖Case 2-1 🤖Case 2-2 🤖Case 3-1 🤖Case 3-2
+---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+
| ● | O | X | | ● | O | X | | ✖ | O | X | | | O | X | | ✖ | O | X | | | O | X |
+---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+
| O | ✖ | X | | O | | X | | O | ● | X | | O | ● | X | | O | | X | | O | ✖ | X |
+---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+
| X | | O | | X | ✖ | O | | X | | O | | X | ✖ | O | | X | ● | O | | X | ● | O |
+---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+
game over next: human(●) next: human(●) next: human(●) next: human(●) game over
(score: +1) min(-1) = -1 min(-1) = -1 min(-1) = -1 min(-1) = -1 (score: +1)
👤Case 1-2-1 👤Case 2-1-1 👤Case 2-2-1 👤Case 3-1-1
+---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+
| ● | O | X | | ✖ | O | X | | ● | O | X | | ✖ | O | X |
+---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+
| O | ● | X | | O | ● | X | | O | ● | X | | O | ● | X |
+---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+
| X | ✖ | O | | X | ● | O | | X | ✖ | O | | X | ● | O |
+---+---+---+ +---+---+---+ +---+---+---+ +---+---+---+
game over game over game over game over
(score: -1) (score: -1) (score: -1) (score: -1)
최대화/최소화 스위칭
- 변수
maximizing에 bool값을 저장- 컴퓨터의 턴에서는 True가 되어서 가능한 케이스 중 가장 큰 점수를 고른다.
- 사람의 턴에서는 False가 되어서 가능한 케이스 중 가장 작은 점수를 고른다.
Result
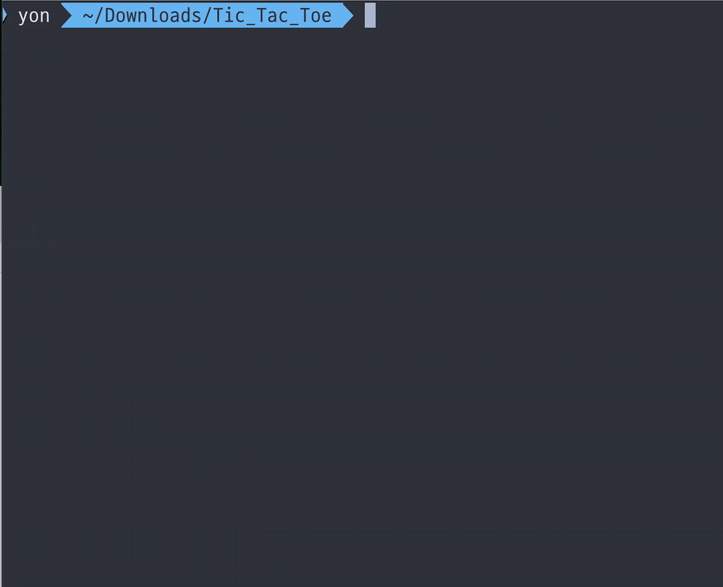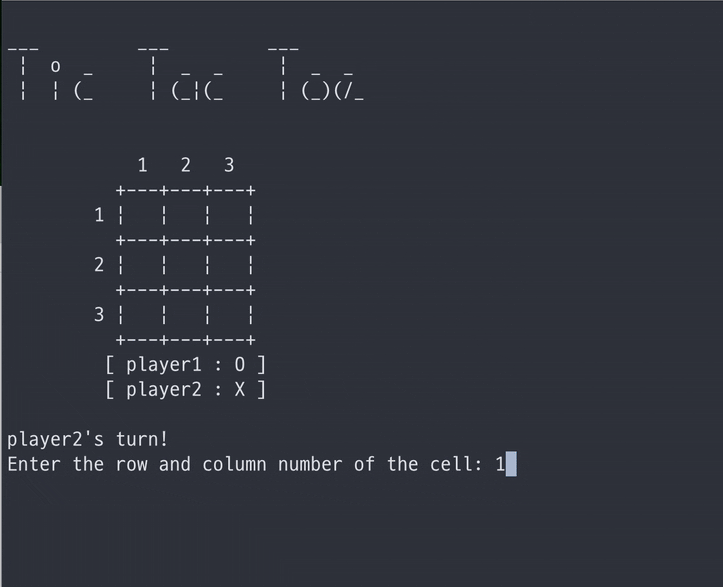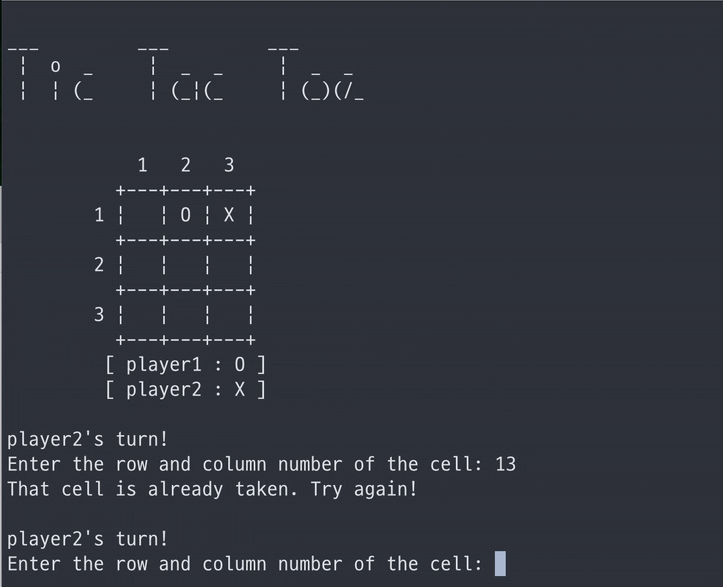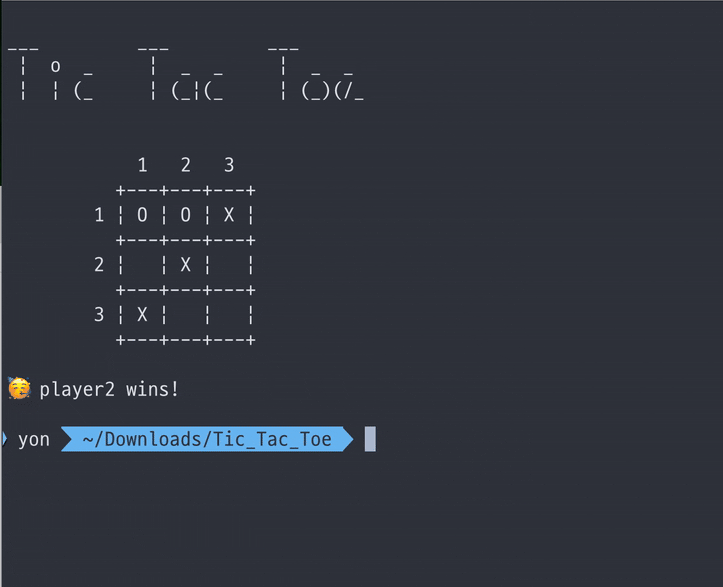
pvp 모드로 다른 사람과 플레이
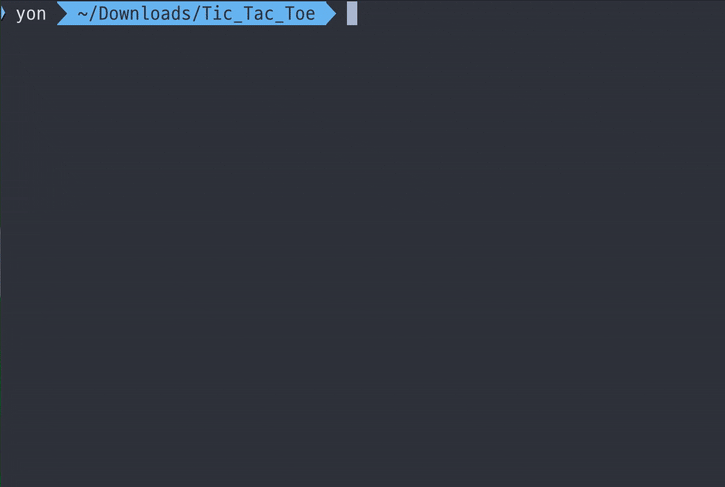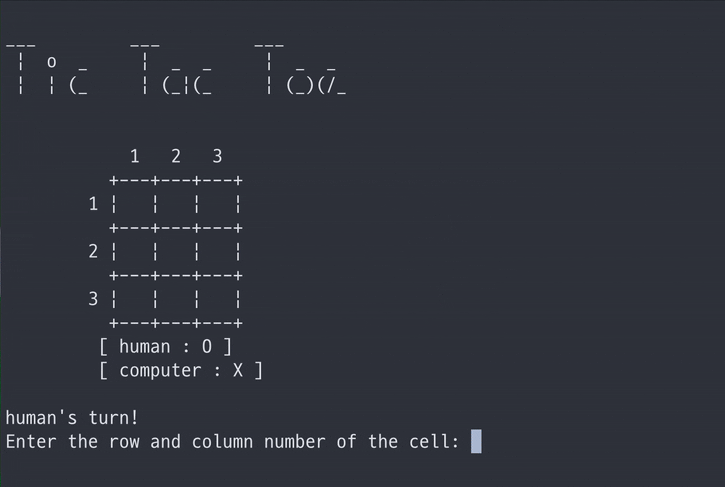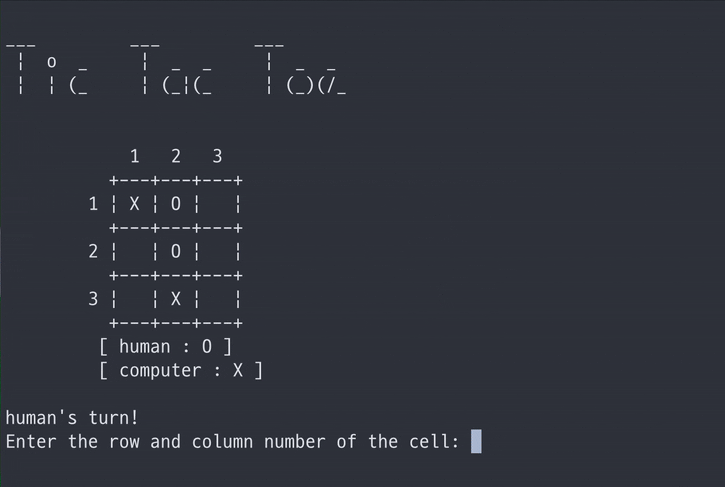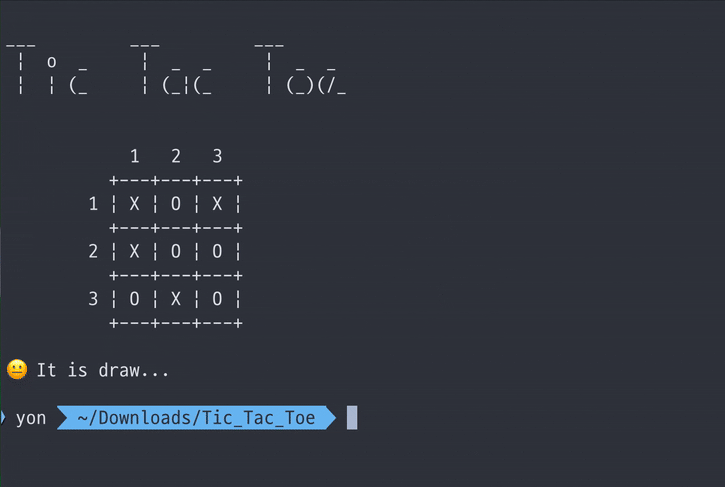
AI 모드에서 hard 레벨로 컴퓨터와 플레이
Future Improvements
- GUI 프로그램으로 구현
- 점수 기록 기능 추가
각 플레이어의 점수를 기록해서 먼저 정해진 점수에 도달하는 쪽이 이기는 기능을 추가한다면 좀 더 경쟁하는 느낌이 날 것이다.
Conclusion
사람과 대결할 때 항상 최적의 선택을 하는 AI 알고리즘을 게임에 적용할 수 있었다. 또 객체 지향 프로그래밍(OOP)을 활용해서 각 기능을 모듈화하고 관리화하는 방법을 익힐 수 있었다.
reference
Minimax algorithm: https://youtu.be/Bk9hlNZc6sE?si=j611ABRB_1IWVc6m&t=3548
Posted on: February 05, 2025